

Ручная настройка прокси для Wi-Fi: пошаговое руководство
21.07.2026 9 мин
ZoomInfo — одна из самых популярных платформ. Бизнес использует ее для сбора данных о компаниях и частных лицах. Платформа позволяет получить детальную информацию: профили фирм, списки сотрудников, должности, прямые номера телефонов и имейлы. Доступны даже данные о выручке. Как собрать этот массив информации масштабно? Самый эффективный метод — веб-скрапинг.
Парсинг ZoomInfo можно выполнять по-разному. Используйте широкий спектр инструментов разведки, включая готовые решения. Или пишите собственные скрипты с нуля.
В этом руководстве мы детально разберем скрапинг ZoomInfo. Обсудим, как это делать, зачем это нужно, частые проблемы и многое другое. Вам нужно готовое или кастомное решение? Тогда этот гайд — то, что вы искали.
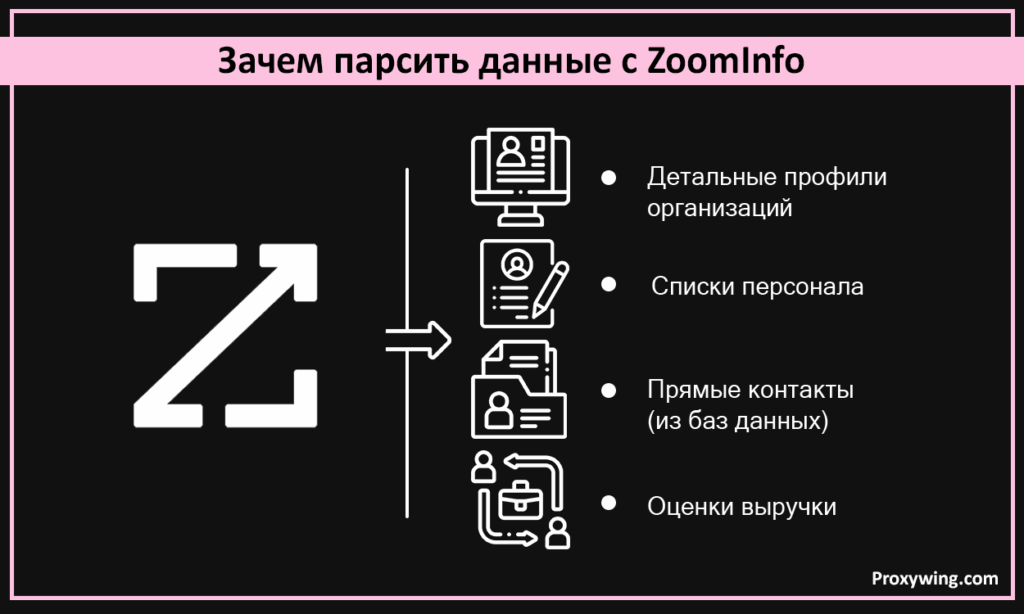
Главная причина — доступ к огромным объемам информации. Вы получаете сведения о компаниях и их сотрудниках. Что именно можно собрать? Детальные профили организаций, фирмографические данные, списки персонала, должности. Доступны прямые контакты (из баз данных), оценки выручки, технологические стеки и сигналы о намерениях.
Бизнес использует эти данные для построения стратегии. Продажи, маркетинг, рекрутинг — сферы применения обширны. Для B2B-компаний эта информация критически важна. Она помогает командам продаж запускать более эффективные B2B-кампании. В целом, бизнес извлекает данные из ZoomInfo для создания списков целевых лидов и обогащения CRM-систем. Также это полезно для изучения рыночных трендов, улучшения охватов и бизнес-разведки.
Избегайте потенциальных штрафов. Вот ключевые моменты, о которых нужно помнить при скрапинге ZoomInfo:
Перед стартом нужно подготовиться. Это поможет избежать сбоев в процессе. Сначала создайте чистое рабочее пространство Python (virtualenv). Это изолирует зависимости.
Вам понадобятся ключевые библиотеки Python. Selenium необходим для страниц, перегруженных JS. Httpx послужит отличным асинхронным HTTP-клиентом. А BeautifulSoup пригодится для парсинга.
Вот процедура, которой можно следовать при настройке среды:
Что нужно для доступа и успешного сбора данных?
Важно понимать структуру данных ZoomInfo до начала работы. Это сэкономит время и ресурсы. Во-первых, страницы ZoomInfo построены на динамическом контенте, управляемом JavaScript. Большинство профилей компаний и людей загружают информацию через встроенные блоки JSON или структурированные HTML-секции.
Понимание организации данных помогает бизнесу. Вы будете точно знать, на что нацелиться при скрапинге и какие инструменты выбрать. Например, страницы компаний обычно содержат основной обзорный раздел. Также есть панели с контактами, фирмография и секции технологий. Профили людей, напротив, включают личные детали, рабочие роли и связи с компаниями. Зная расположение каждой секции, вы сможете извлечь данные максимально точно.
Вот исчерпывающий список типов данных о компаниях, которые собирают инструменты скрапинга:
Следуйте этим шагам, чтобы найти целевые элементы и получить доступ к данным:
Вот высокоуровневый рабочий процесс для сбора данных с ZoomInfo:
Вот процедура извлечения информации о компании из ZoomInfo:
Пример фрагмента кода:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
def scrape_all_text():
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=True)
page = browser.new_page()
page.goto("https://zoominfo.com/company_name")
page.wait_for_load_state("networkidle")
html = page.content()
browser.close()
soup = BeautifulSoup(html, "html.parser")
all_text = soup.get_text(separator=" ", strip=True)
return all_text
result = scrape_all_text()
print(result)
Этот код извлекает весь видимый текст со всей веб-страницы (https://zoominfo.com/company_name).
При парсинге платформ вроде ZoomInfo, где хранятся чувствительные и ценные данные, вы можете столкнуться со строгими анти-бот системами. Давайте разберем, как обойти эти ограничения.
С ротируемыми резидентными прокси ваши запросы распределяются по разным IP-адресам. Кажется, что подключения идут от множества разных пользователей. Это снижает риск бана IP. Каждый адрес можно настроить так, чтобы он оставался в рамках лимитов ZoomInfo. Кроме того, резидентные прокси используют IP реальных домашних устройств. ZoomInfo сложнее обнаружить и заблокировать их. Они просто не выглядят как прокси.
Использование инструментов скрытой автоматизации позволяет вашему браузеру вести себя как реальный пользователь. Это скрывает индикаторы, выдающие активность робота. Такие инструменты корректируют параметры: отпечатки браузера (fingerprints), строки user-agent и другие мелкие детали. На них и смотрят анти-бот системы. В сценариях, где появляется CAPTCHA для проверки человечности, используйте сервисы для её решения. Это поможет вашему инструменту скрапинга преодолевать преграды бесшовно.
Для крупных проектов придется парсить данные с сотен или даже тысяч страниц. Один из способов достичь такого масштаба — запуск нескольких инстансов браузера. Или использование асинхронных стратегий для быстрой обработки больших датасетов. Чтобы оптимизировать процесс, повторно используйте сессии браузера, обрабатывайте пагинацию автоматически и полагайтесь на эндпоинты со структурированными данными, если они доступны.
Страницы поиска и каталоги обычно показывают результаты на нескольких веб-страницах. Чтобы собрать все данные по запросу, ваш инструмент должен уметь находить кнопку «Далее» или ссылки пагинации и последовательно переходить по ним, шаг за шагом.
Каждый раз при загрузке новой страницы результатов повторяйте процесс извлечения. Сохраняйте записи. Это пошаговое движение гарантирует, что вы захватите полный набор данных, а не только первую страницу выдачи.
Платформы разведки, такие как ZoomInfo, обычно предоставляют внутренние ссылки на компании-партнеров, конкурентов или связанные организации. Ваши инструменты скрапинга могут переходить по этим внутренним ссылкам. Это логично расширяет ваш набор данных. Дополнительные профили собираются без ручного поиска каждого из них.
Эта техника называется рекурсивный краулинг. Собрав данные с одного профиля, ваш инструмент находит релевантные ссылки на странице. И посещает их как новые цели. Создается цепочка связанных страниц. Это дает гораздо более богатый датасет при сохранении организованной структуры.
Мы уже упоминали ранее: ZoomInfo и подобные платформы могут заблокировать ваше соединение. Особенно если заметят необычное поведение при скрапинге. Чтобы избежать блокировки, мы рекомендуем использовать прокси с ротацией IP-адресов.
При использовании ротируемых IP ZoomInfo будет видеть эти подключения так, будто они идут с разных устройств. Это позволяет вашему инструменту отправлять множество запросов, не триггеря детекторы ботов.
Другие техники, помогающие избежать бана, включают добавление коротких случайных задержек между загрузками страниц. Также используйте реалистичные заголовки браузера, соответствующие обычному трафику. Поддерживайте постоянные отпечатки браузера. Избегайте любого поведения, которое выглядит автоматизированным в процессе парсинга.
Пример кода полного инструмента для скрапинга:
from time import sleep
import random
import json
from pathlib import Path
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
START_URL = "https://zoominfo.com/company_name" # replace with the exact URL you intend to scrap
NEXT_SELECTOR = "a.next" # CSS selector for the site's "next" link
OUT_FILE = Path("playwright_results.jsonl")
def polite_sleep(min_s=0.8, max_s=1.8):
sleep(random.uniform(min_s, max_s))
def extract_all_text(html: str) -> str:
soup = BeautifulSoup(html, "html.parser")
return soup.get_text(separator=" ", strip=True)
def save_record(record: dict):
OUT_FILE.parent.mkdir(parents=True, exist_ok=True)
with OUT_FILE.open("a", encoding="utf-8") as f:
f.write(json.dumps(record, ensure_ascii=False) + "\n")
def run_simple_crawl(start_url: str, max_pages: int = 5, headless: bool = True):
with sync_playwright() as pw:
browser = pw.chromium.launch(headless=headless)
page = browser.new_page(user_agent="EducationalScraper/1.0")
url = start_url
pages = 0
try:
while url and pages < max_pages:
page.goto(url)
# wait until network is idle so JS can finish
page.wait_for_load_state("networkidle")
polite_sleep()
html = page.content()
text = extract_all_text(html)
save_record({"url": url, "text_preview": text[:1000], "_scraped_at": __import__("time").time()})
pages += 1
print(f"Saved page {pages}: {url}")
# try to find and click a Next link (if present)
next_el = page.query_selector(NEXT_SELECTOR)
if next_el:
try:
next_el.click()
polite_sleep()
url = page.url
continue
except Exception:
break
else:
break
finally:
browser.close()
if __name__ == "__main__":
run_simple_crawl(START_URL)Приведенный выше скрипт на Python использует Playwright для рендеринга страниц, BeautifulSoup для извлечения всего видимого текста, переходит по одной ссылке «Далее» до установленного лимита страниц и сохраняет превью текста каждой страницы в файл JSONL.
При веб-скрапинге ZoomInfo вы можете столкнуться с некоторыми ошибками. Давайте обсудим распространенные проблемы и способы их решения.
Эта статья дает полное понимание того, как можно парсить данные с ZoomInfo. Будь то информация о компании, детали сотрудников или данные о ключевых фигурах в любой индустрии. Все инструменты скрапинга, упомянутые в этом руководстве, включая Playwright, httpx и BeautifulSoup, являются открытым ПО. Они бесплатны для использования.
Однако помните об этике сбора данных. Следуйте условиям обслуживания ZoomInfo, чтобы избежать юридических проблем. Если вы столкнулись с трудностями, такими как лимиты запросов или блокировки IP, использование резидентных прокси с ротацией IP поможет обойти эти ограничения. ProxyWing предоставляет прокси для скрапинга, которые дают вам доступ к миллионам IP в более чем 190 странах.
Статью написал:

Руководитель продукта и операций поддержки
Максимилиан выстроил службу поддержки Proxywing с нуля, превратив разрозненные процессы в структурированный, самостоятельный отдел с задокументированными рабочими процессами, чёткими путями эскалации и стабильным качеством сервиса. Сегодня он выступает связующим звеном между CEO и инженерными командами, переводя бизнес-приоритеты в конкретные задачи и обеспечивая своевременную реализацию проектов, связанных с прокси-инфраструктурой. Академическая база в области психологии — с формальной подготовкой в методологии исследований и анализе данных — усиливает его подход к проектированию процессов и интерпретации обратной связи от пользователей. Вне работы Максимилиан исследует пересечения человеческого поведения, принятия решений и продуктового мышления.
Все статьи автора (63)
