

Ручная настройка прокси для Wi-Fi: пошаговое руководство
21.07.2026 9 мин
Когда речь заходит о сборе больших массивов данных из сети, на сцену выходят два главных инструмента: веб-скрапер (web scraper) и веб-краулер (web crawler). Часто многие полагают, что это одно и то же. Это ошибка. Разница есть и она существенна.
Веб-краулинг помогает находить страницы для последующей обработки. Веб-скрейпинг — это сам процесс извлечения данных. Эти инструменты могут работать в тандеме. Каждый из них выполняет свою, критически важную задачу в общем процессе сбора информации.
В этой статье мы разберем ключевые отличия краулеров от скрейперов. Посмотрим, как они дополняют друг друга в реальных проектах. Мы детально обсудим механизмы их работы. Вы поймете, зачем они нужны и какие роли играют. Не будем терять времени, приступим к сравнению.
Веб-краулинг — это автоматизированная разведка. Процесс обнаружения и сканирования страниц на просторах интернета. Эту работу выполняет специальная программа — веб-краулер.
Он перемещается по ссылкам. От одной страницы к другой. Шаг за шагом. Попутно собирает ключевые детали о каждом посещенном узле. Главная цель краулера — понять структуру сайта. Составить его карту.
Поисковые гиганты, такие как Google, используют краулеры именно для этого. Их боты посещают миллионы сайтов. Сканируют их. Сохраняют важную информацию в своих базах данных.
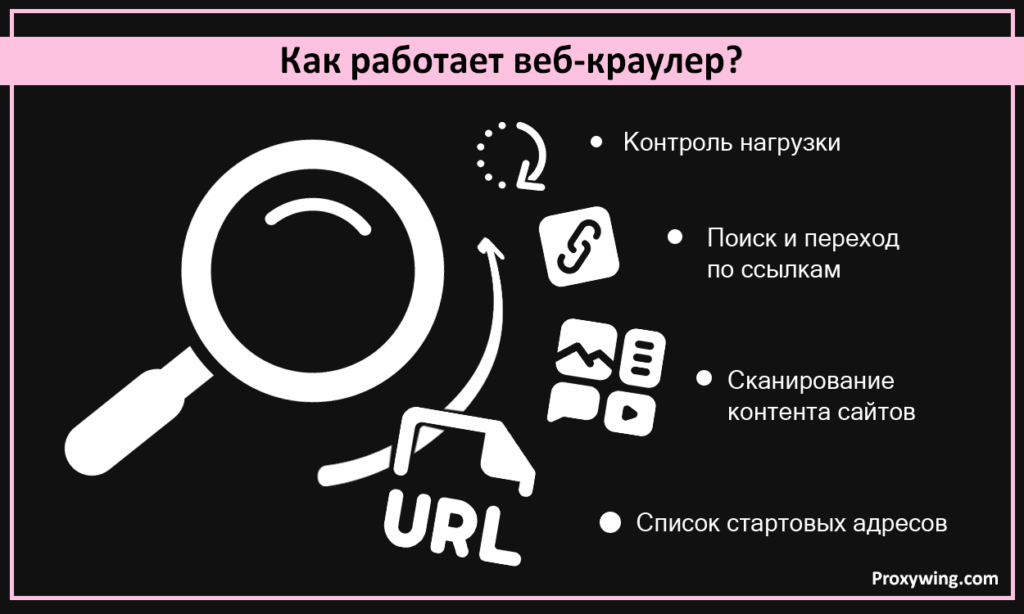
Всё начинается со списка стартовых адресов. Их называют seed URLs.
Краулер заходит на эти страницы. Сканирует контент. Находит внутренние и внешние ссылки. И переходит по ним. Если бот попал на главную страницу, он пойдет дальше, вглубь сайта. Используя навигационные ссылки. Вот почему внутренняя перелинковка — один из столпов грамотного SEO.
Чтобы не “положить” сайт чрезмерной нагрузкой, умные краулеры используют логику планирования. Они сами решают, какие страницы посетить первыми. И как часто туда возвращаться.
Вспомним Google или Bing. Как мы уже говорили, они используют краулеры непрерывно. Цель — найти новые страницы или обновления на старых. После сканирования данные отправляются в индекс поисковой системы. Там страницы анализируются и ранжируются по релевантности.
Без краулеров Google был бы “слеп”. Он бы просто не знал, какой контент размещен на странице и как он связан с остальным сайтом.
Веб-скрейпинг — это технология добычи структурированных данных. Источник — страницы веб-сайтов или веб-приложений.
Забудьте о ручном копировании. Никакого «Ctrl+C — Ctrl+V». Скрейперы собирают информацию автоматически. Они превращают неструктурированный веб-контент в удобные форматы. CSV, JSON, записи в базе данных. Когда данные структурированы, с ними можно работать. Эффективно анализировать их.
Процесс начинается с отправки HTTP-запроса на целевую страницу. Скрейпер скачивает HTML-код. Затем начинается парсинг.
Программа прочесывает код в поисках нужного. Это могут быть цены на товары и описания. Любые детали, на которые настроен скрейпер. Извлекли информацию? Отлично. Теперь скрейпер сохраняет её в нужном формате. Дальше — аналитика или автоматизация процессов.
Современные скрейперы пошли еще дальше. Они умеют работать со страницами, отрисованными через JavaScript. Для этого используются headless-браузеры (браузеры без графического интерфейса). Это позволяет добывать данные даже с самых современных, динамических сайтов.
Сценариев использования — масса. Вот самые популярные причины, почему бизнес и исследователи обращаются к скрейпингу:
Инструмент нужно выбирать под задачу. И под ваши приоритеты. Вот основные типы:
Подведем итог. В чем разница?
| Характеристика | Веб-краулер | Веб-скрейпер |
| Цель | Обнаружение страниц, навигация, сбор URL-адресов | Извлечение конкретных данных со страниц |
| Входные данные | Стартовые URL (Seed URLs) | URL, предоставленные вручную или краулером |
| Результат | Список найденных ссылок | Структурированные данные (CSV, JSON, БД) |
| Охват | Широкое исследование сайта или всей сети | Точечное извлечение с выбранных страниц |
| Принцип работы | Автоматически переходит по ссылкам, строит карту сайта | Парсит HTML, забирает нужный контент |
| Типичные задачи | Индексация для SEO, аудит сайта, поиск | Трекинг цен, сбор лидов, исследования |
| Зависимость | Работает автономно, дает ссылки скрейперу | Часто зависит от краулера (нужны адреса) |
Теперь мы знаем разницу. Посмотрим на синергию. Как использовать эти инструменты в связке?
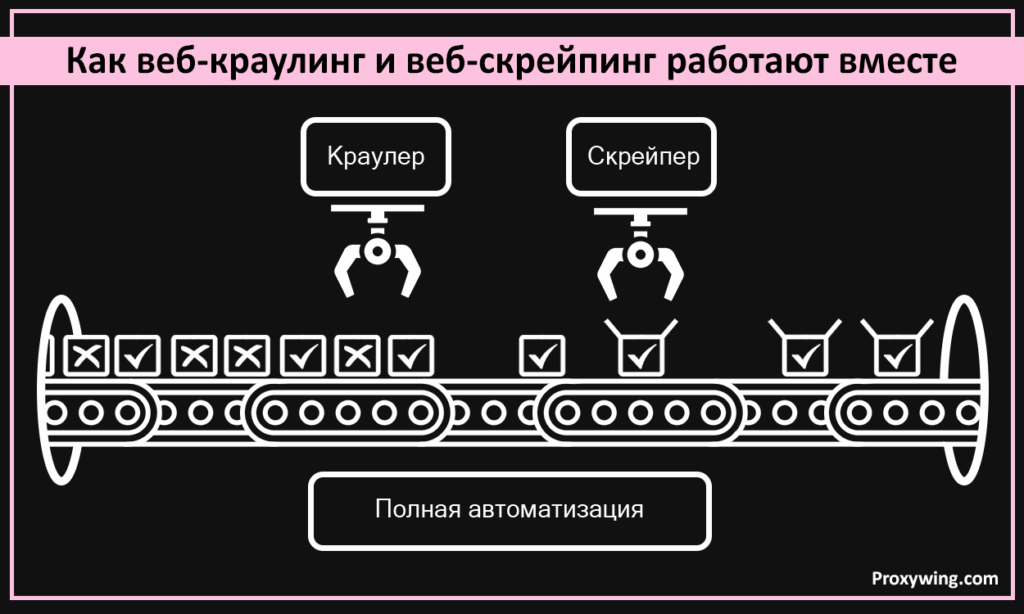
Бизнес часто комбинирует их. Задача краулера — разведка. Он находит и собирает все релевантные страницы на сайте. Как только страницы найдены, в игру вступает скрейпер. Он посещает каждый адрес. Обрабатывает контент. Извлекает именно те данные, которые были нужны.
Итог? Полная автоматизация. От обнаружения страниц до получения готовой таблицы с данными. Процесс становится быстрым и эффективным.
Данные — это топливо для решений. Скрейпинг дает бизнесу инсайты. Позволяет опираться на факты, а не на интуицию. Используя скрейперы, компании могут:
Скрейпинг критически важен. Особенно для тех, кто хочет принимать решения на основе реальной картины рынка.
Скрейпинг стал стандартом во многих отраслях: финансы, медицина, технологии. Вот реальные примеры использования:
В теории всё звучит просто. На практике сбор данных — это полоса препятствий. Вы столкнетесь с вызовами:
У вас есть сайт? Веб-приложение? Вы хотите быть в топе Google? Тогда сделайте свой ресурс доступным для краулеров.
Это называется crawlability (сканируемость). Если боты поисковиков спотыкаются на вашем сайте, забудьте о высоких позициях. Вас просто не проиндексируют.
Чтобы улучшить сканируемость, владельцам сайтов нужно:
Веб-краулеры и скрейперы — мощные инструменты. Вместе они повышают эффективность сбора данных в разы. Краулеры находят страницы. Скрейперы забирают с них самое важное.
Для бизнеса, живущего данными, этот процесс — основа успеха.
Владельцам сайтов стоит помнить и об обратной стороне. Облегчите жизнь краулерам — и поисковики отблагодарят вас трафиком. Резюмируя: это разные инструменты. Но в связке они превращают хаос веба в упорядоченную базу знаний.
Статью написал:

Генеральный директор
Даниил основал Proxywing с чётким видением: предоставлять премиальные прокси-решения, на которые бизнес и частные пользователи могут положиться без компромиссов. Его экспертиза в международном бизнесе и B2B-стратегии обеспечивает расширение компании на рынки ЕС, США и Азии, а практический подход гарантирует, что качество продукта — от 99% аптайма до оперативной поддержки — остаётся главным приоритетом. Даниил мыслит масштабно: совершенствует внутренние процессы компании, выявляет рыночные возможности и внедряет передовые технологии, чтобы оставаться впереди конкурентов. Когда он не занят развитием компании, то направляет энергию на изучение новых бизнес-направлений и стратегических партнёрств.
Все статьи автора (58)Главная роль краулера — найти веб-страницы и их URL. Сохранить их в базе. Скрейперы же нужны для извлечения конкретной информации с этих страниц. Краулер находит адреса. Скрейпер идет по ним и добывает данные.
Да. Если у вас уже есть список URL, с которых нужно собрать данные, краулер не нужен. Его роль — именно поиск ссылок.
Да, это законно. Но этика важна. Бизнес и частные лица должны соблюдать условия использования целевых сайтов. И помнить об авторских правах при использовании собранных данных.
Есть универсальные бойцы. Scrapy. Связка BeautifulSoup + Requests. Playwright. Если ищете решение “два в одном”, эти варианты — одни из лучших на рынке.
Они ищут новый контент. Краулеры заходят на сайты, переходят по ссылкам, составляют карту структуры. Все найденные URL попадают в индекс. Именно этот индекс использует поисковик, когда вы вводите запрос, чтобы выдать вам самые релевантные результаты.

