

Manual Proxy Setup for WiFi: How to Configure It Step by Step
21.07.2026 12 min
When collecting large amounts of data from the web, the two commonly used tools are a web scraper and a web crawler. It is common to assume that these two tools are the same, but they aren’t. Web crawling helps discover pages to scrape, while web scraping is the actual process of collecting the data. Crawlers and scrapers can be used together and each tool handles an equally important task in the data collection process.
In this web crawler vs. web scraper article, we discuss the key differences between these tools and how they are used together in data scraping projects. This guide includes detailed explanations of how they work, why you need them, the key differences in their roles, and more. Without wasting any more time, let’s get started with this web crawling vs web scraping comparison.
Web crawling is an automated process for discovering and scanning web pages of different websites on the internet. A web crawler is used to execute this process. It crawls through links from one page to another, collecting crucial details about each page visited. The main goal of the crawler is to understand the map and structure of a website.
Search engines such as Google use crawlers to discover webpages on the internet. Their crawlers visit different websites on the internet, scan these pages, and store the important information in their database.
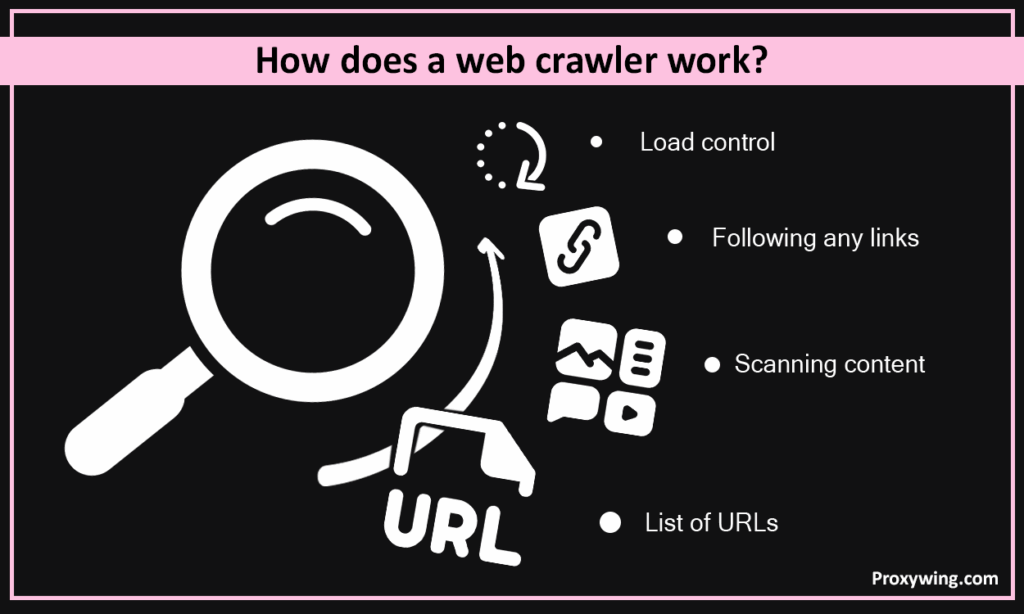
A crawler starts with a list of URLs known as seed URLs. It then visits each of these pages, scans the content, and then follows any internal or external links it finds. So, if a crawler visits a homepage of a website, it will move to other pages using the links from the homepage. That’s why internal linking is one of the most recommended SEO practices.
To avoid overloading a single website, crawlers use scheduling logic to decide which pages to visit first and how often to return to them.
As stated earlier, search engines like Google and Bing use crawlers to continuously scan websites to discover new pages and updates. After scanning the web pages, these crawlers send the data to the search engine’s index, where pages are analyzed and ranked based on relevance. Without these crawlers Google would not know what content is on each webpage and how it is related to the rest of the content on a given website.
Web scraping is the process of extracting structured data from webpages of a given website or web application. Instead of manually copying and pasting data from a web page, scrappers collect it automatically by turning unstructured web content into usable formats like CSV, JSON, or database entries. When data is structured, it is much easier and efficient to analyze.
A web scraper starts by sending a HTTP request to the target webpage and then downloads the discovered HTML content. It then parses data in the HTML looking for important information such as prices of goods and any other details it is configured to look for. After extracting the targeted information, the scraper stores it in a structured format for further analysis or automation.
Modern scrappers are also designed to handle JavaScript-rendered pages by using headless browsers. This allows them to scrap data from modern websites that do include a lot of Javascript elements.
There are several real world use cases for web scrapers. Some of the common reasons for scraping data from targeted websites include:
There are several types of web scrapers that you can choose based on the task at hand and your priorities. Some of the common types include:
Here is a summary of how web scrappers and crawlers differ.
| Feature | Web Crawler | Web Scraper |
| Purpose | Discovering, navigating web pages, and collecting urls | Extract specific data from web pages, focusing on only what matters |
| Main Input | Seed URLs or starting points | URLs provided manually or by a crawler |
| Main Output | List of discovered URLs | Structured data (CSV, JSON, database entries) |
| Scope | Broad exploration of entire sites or the wider web | Extracts specific data from selected pages |
| Operation Style | Follows links automatically and maps site structure | Parses HTML and extracts targeted content |
| Typical Use Cases | SEO indexing, site audits, large-scale discovery | Price tracking, lead generation, research, automation |
| Dependency | Works independently but often provides links for scrapers | Often relies on crawlers to supply URLs for extraction |
Now that we know the differences between scrappers and crawlers, let’s explore how these two tools can be used together.
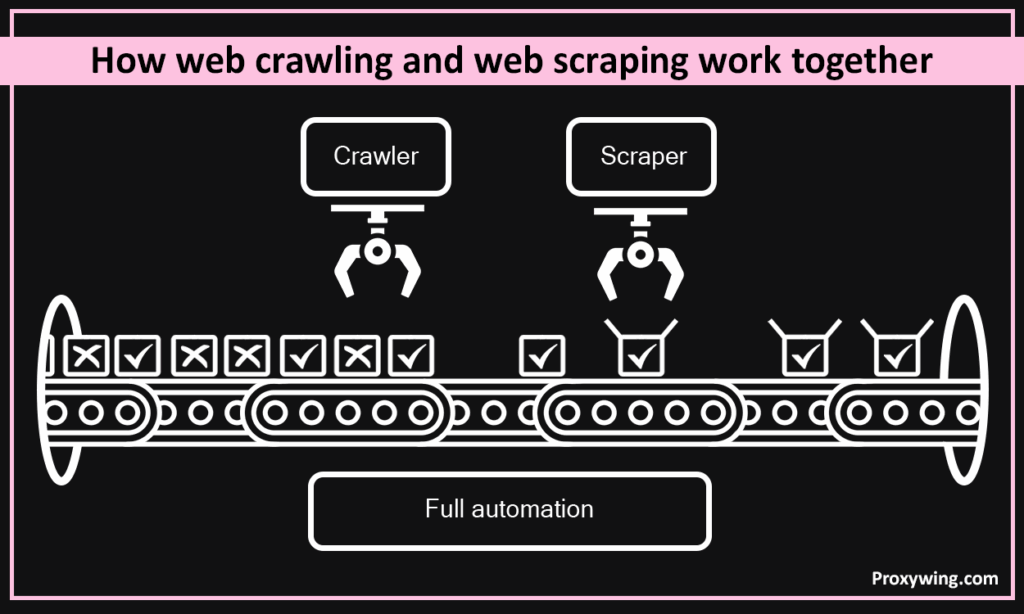
Businesses often use web crawling and web scraping together to collect data. The crawler’s job is to discover and gather all the relevant pages on a website. After the pages are found, the scraper visits each one, processes the content, and extracts the specific data it was configured to collect. Using both tools together automates page discovery and data extraction, making the whole workflow faster and more efficient.
Web scraping provides businesses with valuable insights that can help them make more data-driven decisions. By using scrappers, business can:
Overall, scraping is a crucial part of research for businesses that intend to make decisions based on real market data and not assumptions.
Data scraping has become an essential part for business in several industries, including finance, health, technology, and more. Let’s explore some of the real world applications to learn more how data scraping is used there:
Web scraping in theory looks simple and straightforward. However, the actual data collection process has several challenges that you need to be aware of. Some of these challenges include:
If you own a website or web application that you need to be visible in search results on platforms like Google, it is important to make your webpage crawlable. If crawlers from search engines find it hard to crawl your webpages, they may not appear in search results.
To improve crawlability, site owners need to:
Web crawlers and scrapers are important tools that can be used together to improve the effectiveness of the data collection process. Crawlers discover web pages, and scrapers collect the important data on those pages. Crawling and scraping are crucial parts of the data collection process, especially for businesses that rely on data to make important decisions.
If you are a website owner, you may also want to make your site easier to crawl to increase the chances of your pages appearing in search engine results for relevant queries. In summary, web crawlers and scrapers are different tools, but when used together, they make data collection far more efficient.
Article written by:

CEO
Daniil founded Proxywing with a clear vision: deliver premium proxy solutions that businesses and individuals can rely on without compromise. His expertise in international business and B2B strategy drives the company's expansion across EU, US, and Asian markets, while his hands-on approach ensures that product quality — from 99% uptime to responsive support — remains the top priority. Daniil focuses on the big picture, refining company processes, identifying market opportunities, and integrating cutting-edge technologies to stay ahead of the competition. When he's not steering the company's growth, he channels his energy into exploring new business ventures and strategic partnerships.
All articles by author (58)The main role of a crawler is to discover webpages and their URLs, which are then saved in a database. On the other hand, scrapers are used to extract specific information from webpages. So, scrapers discover URLs and send them to scraper to handle the data extraction.
Yes, scraping can be done without crawling as long as you know extra URLs you intend to extra data from. The main role of crawling is to discover URLs.
Yes, web scraping is legal, but it has to be done ethically. Businesses and individuals scraping data need to follow the terms of the target websites and also remember to respect copyright laws when using the collected data.
Some of the tools that can handle both crawling and scraping include Scrapy, BeautifulSoup + Requests, and Playwright. If you’re searching for two-in-one tools, these are some of the best choices available.
Search engines use web crawlers to find new content on the internet. The crawlers visit websites, follow links, and map out the structure of each site. They then store all the found URLs in an index. This indexed content is what search engines use to rank results for a given query based on relevance.

